在 Kubernetes 上部署 Apache Flink:生产实战指南
本文基于 Flink 1.15.2 + Kubernetes 的生产环境部署实践。
一、架构概览
Flink 在 Kubernetes 上采用经典的 JobManager + TaskManager 主从架构,JobManager 负责作业调度与协调,TaskManager 承载实际的计算任务。
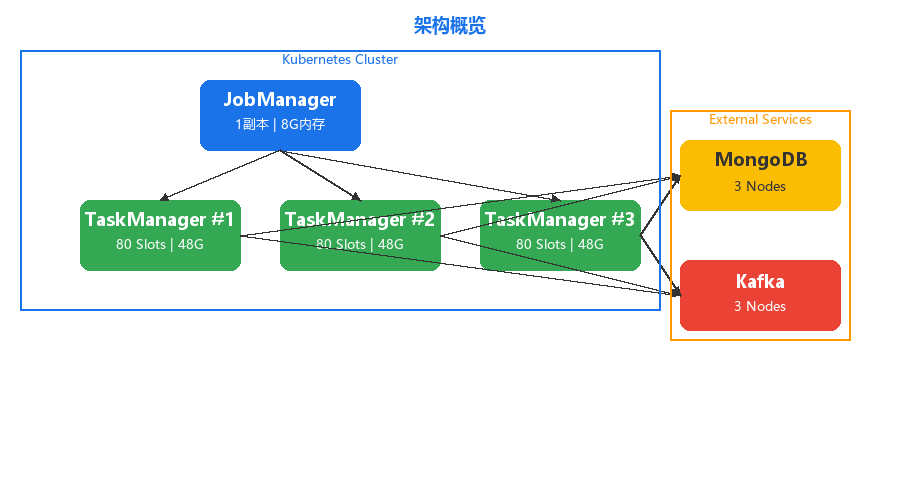
资源分配一览
| 组件 | 作用 | 副本数 | Task Slots | 内存配置 |
|---|---|---|---|---|
| JobManager | 作业调度、Checkpoint 管理、协调 | 1 | — | 8G |
| TaskManager | 执行计算任务 | 3 | 80/Pod | 48G |
| 总计 | — | 4 | 240 | — |
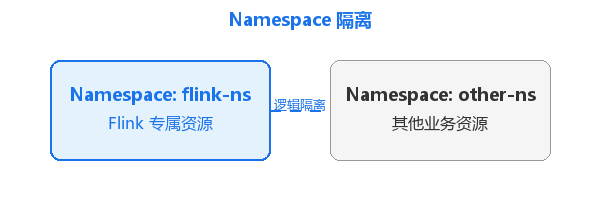
二、Namespace 隔离
为 Flink 创建独立 Namespace,实现资源与权限的逻辑隔离:
apiVersion: v1
kind: Namespace
metadata:
name: flink-ns
三、Service 设计
我们定义了两个 Service,分别处理内部通信与外部访问:
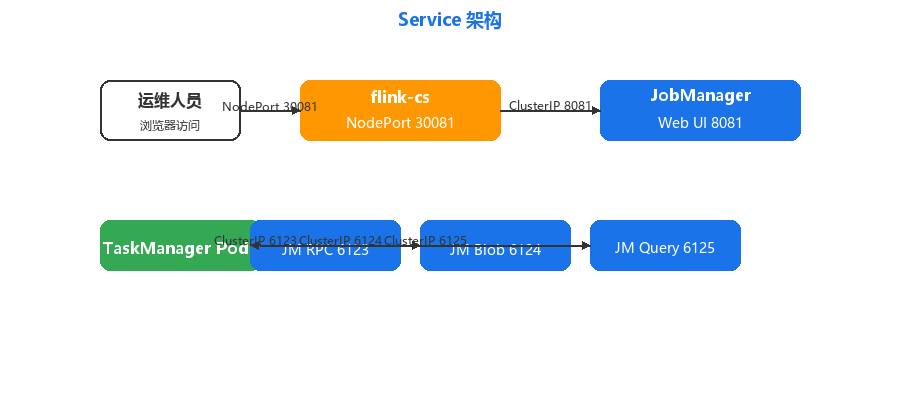
3.1 内部通信 Service(ClusterIP)
apiVersion: v1
kind: Service
metadata:
name: flink-jobmanager
namespace: flink-ns
spec:
type: ClusterIP
ports:
- name: rpc
port: 6123 # JobManager RPC
- name: blob
port: 6124 # Blob Server
- name: query
port: 6125 # Queryable State
- name: ui
port: 8081 # Web UI
selector:
app: flink-jobmanager
3.2 外部访问 Service(NodePort)
apiVersion: v1
kind: Service
metadata:
name: flink-cs
namespace: flink-ns
spec:
type: NodePort
ports:
- port: 8081
targetPort: 8081
nodePort: 30081 # 外部访问端口
selector:
app: flink-jobmanager
访问 Flink Web UI:http://<任意节点IP>:30081
四、关键运行参数
通过 FLINK_PROPERTIES 环境变量注入 Flink 配置,这是 K8s 部署的推荐方式:
4.1 Checkpoint 配置
execution.checkpointing.interval: 10min
execution.checkpointing.tolerable-failed-checkpoints: 100
- 每 10 分钟 执行一次 Checkpoint,平衡数据安全性与性能开销
- 允许 100 次 Checkpoint 失败容忍,避免偶发故障导致作业中断
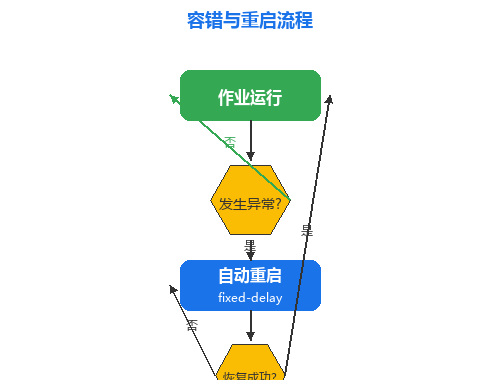
4.2 容错与重启策略
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 2147483647
采用 固定延迟重启策略,重试次数设为 Integer.MAX_VALUE,确保作业在异常情况下持续自动恢复 —— 这在生产环境中至关重要。
4.3 心跳配置
heartbeat.interval: 10000
heartbeat.timeout: 120000
心跳间隔 10 秒,超时阈值 120 秒。较长的超时时间适应 Kubernetes 环境中可能的网络波动和容器调度延迟,防止误判 TaskManager 失联。
4.4 内存配置
# JobManager
jobmanager.memory.process.size: 8G
# TaskManager
taskmanager.memory.process.size: 48G
五、外部服务连通
Flink 作业依赖 MongoDB 和 Kafka 集群,通过 hostAliases 在 Pod 内配置静态域名映射,避免依赖集群 DNS 解析外部服务:
hostAliases:
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "mongoserver1"
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "mongoserver2"
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "mongoserver3"
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "kafka-server01"
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "kafka-server02"
- ip: "xxx.xxx.xxx.xxx"
hostnames:
- "kafka-server03"
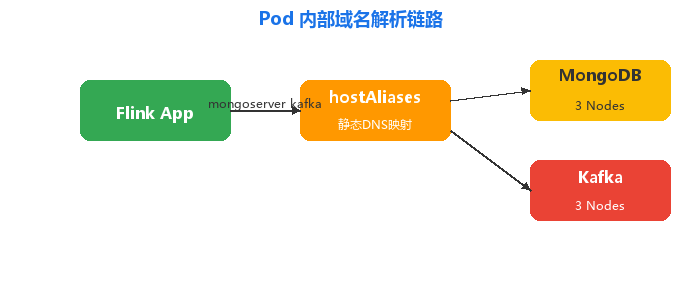
为什么选择 hostAliases?
| 方案 | 优点 | 缺点 |
|---|---|---|
| hostAliases | 配置简单、Pod 内即时生效、无需依赖外部 DNS | IP 变化时需更新 YAML |
| 集群 CoreDNS | 集中管理、自动生效 | 需要配置外部 DNS 转发,复杂度高 |
| 外部 Service + Endpoint | K8s 原生方案 | 配置繁琐,需维护 Endpoint 对象 |
生产环境中外部服务 IP 通常稳定不变,hostAliases 是最简单可靠的选择。
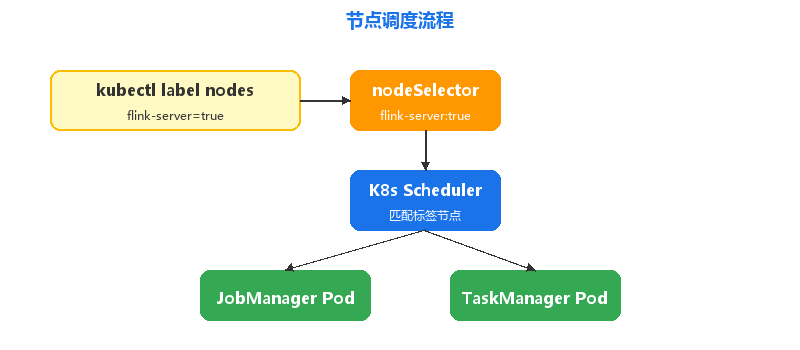
六、节点调度策略
使用 nodeSelector 将 Flink Pod 调度到专属计算节点,保障资源独占:
nodeSelector:
flink-server: "true"
节点打标签
部署前需要为目标节点打标签:
kubectl label nodes stream-node-01 flink-server=true
kubectl label nodes stream-node-02 flink-server=true
kubectl label nodes stream-node-03 flink-server=true
为什么需要 nodeSelector?
- 资源独占:TaskManager 单 Pod 配置 48G 内存,需要物理节点有充足资源
- 避免竞争:防止 Flink 与其他业务争抢 CPU/内存,保障实时计算稳定性
- 网络亲和:计算节点与外部服务(MongoDB/Kafka)网络拓扑更近,降低延迟
七、完整部署流程

步骤 1:节点打标签
kubectl label nodes stream-node-01 flink-server=true
kubectl label nodes stream-node-02 flink-server=true
kubectl label nodes stream-node-03 flink-server=true
步骤 2:执行部署
kubectl apply -f flink.yaml
步骤 3:检查 Pod 状态
kubectl get pod -n flink-ns -o wide
预期输出:
NAME READY STATUS RESTARTS AGE IP NODE
flink-jobmanager-xxxxxxxxxx-xxxxx 1/1 Running 0 60s 10.x.x.x stream-node-01
flink-taskmanager-xxxxxxxxxx-xxxx1 1/1 Running 0 60s 10.x.x.x stream-node-01
flink-taskmanager-xxxxxxxxxx-xxxx2 1/1 Running 0 60s 10.x.x.x stream-node-02
flink-taskmanager-xxxxxxxxxx-xxxx3 1/1 Running 0 60s 10.x.x.x stream-node-03
步骤 4:排查日志(如需)
kubectl -n flink-ns logs <pod-name> --all-containers=true
八、核心配置速查表

| 配置项 | JobManager | TaskManager | 说明 |
|---|---|---|---|
| Checkpoint 间隔 | 10min | 10min | 保障数据安全 |
| Checkpoint 容忍 | 100 | 100 | 防止偶发故障中断 |
| 重启策略 | fixed-delay | fixed-delay | 自动恢复 |
| 重试次数 | MAX | MAX | 最大限度可用性 |
| 心跳间隔 | 10s | 10s | 健康检测 |
| 心跳超时 | 120s | 120s | 适应 K8s 环境 |
| 进程内存 | 8G | 48G | 资源保障 |
| Task Slots | — | 80/Pod | 单 Pod 高并行度 |
九、实践总结

| 要点 | 说明 | 核心收益 |
|---|---|---|
| Namespace 隔离 | 独立命名空间 flink-ns |
资源冲突避免,权限管控清晰 |
| 双 Service 设计 | ClusterIP 内部 + NodePort 外部 | 通信安全 + 运维便捷 |
| 极限容错配置 | fixed-delay + MAX 重试 | 作业永不停歇 |
| hostAliases 连通 | Pod 内静态域名映射 | 外部服务稳定可达 |
| nodeSelector 独占 | 调度到专属计算节点 | 资源充足,避免竞争 |
| 80 Slots / Pod | 单 Pod 高并行度 | 减少 Pod 数量,降低调度开销 |



